这篇文章以绘画这个垂直领域为切入点,介绍下 aigc 能如何优化当前的绘画工作流。以此来启发一下在当下时间点中,另一个与我距离较远的行业中,aigc 已经能做到什么,可能带来新的什么,我们又能做些什么。
简单原理#
下面以我的理解,以扩散模型(Diffusion)为例,简单说一下它的原理。
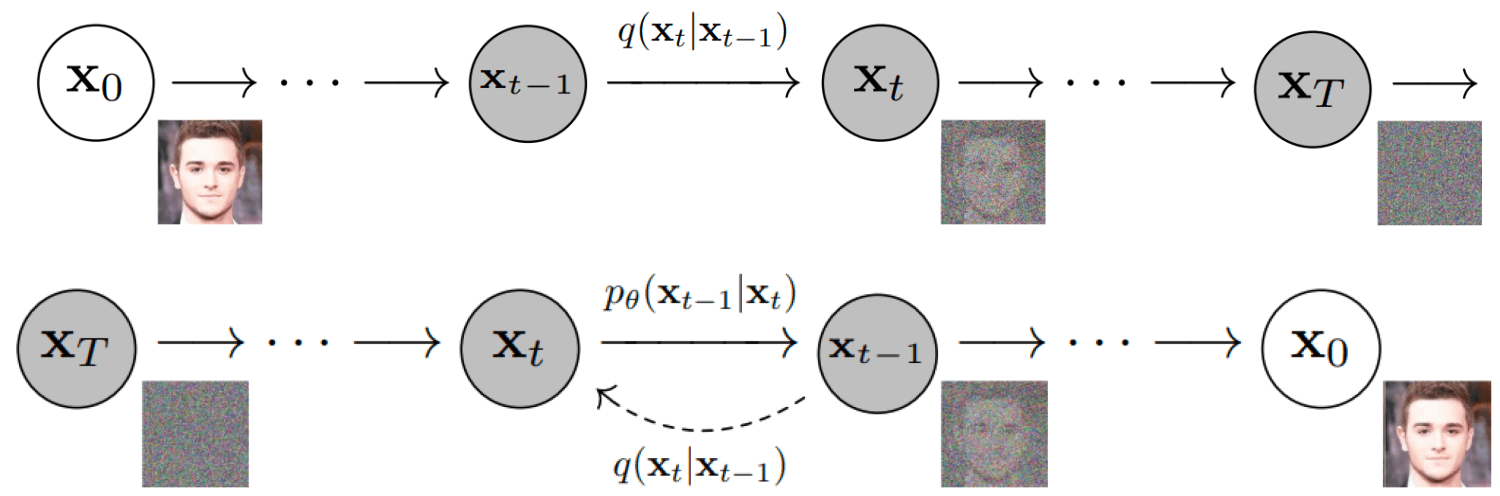
训练过程
我们对原本的图片加噪点,让图片逐渐变成纯噪点图;再让 AI 学习这个过程的逆过程,也就是如何从一张噪点图得到一张有信息的高清图。之后再用条件(比如描述文字或者图片)去控制这个过程,让他知道什么条件该怎么迭代去噪,生成特定的图形。
潜在空间(latent space)
一张 512x512 分辨率的图片,就是一组 512 * 512 * 3 的数字,如果直接对图片进行学习,相当于 AI 要处理 786432 维的数据,这对算力、计算机性能要求很高。所以我们需要将信息压缩,压缩后的空间称为「潜在空间」。
如果我们有 10000 个人的信息列表,想去找两个可能是兄弟的人,如果我们遍历每行处理,那处理的量就有 10000。但如果有这样一个三维坐标系,代表人的潜在空间,三个轴分别为身高、体重、生日,我们在这个三维空间中找两个相邻的点,那么这两个相邻的点代表的人就会有较大的概率是相似的,这样多维的信息对 ai 来讲处理起来更得心应手。
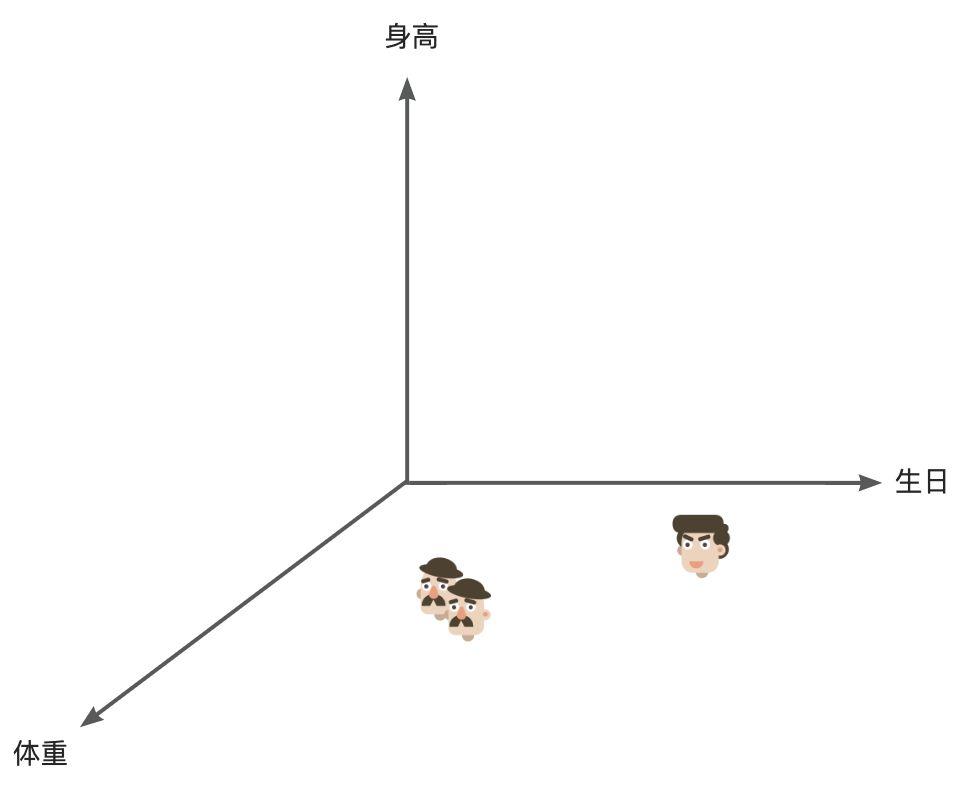
人的认知其实也会这样,认识一类新事物时,会下意识的去进行特征归类,进行多维度的打标。比如我们能很轻易的分辨椅子和桌子不是同类,因为我们在体积这个维度上,他们是明显不同的。
ai 也能做到同样的事情,将本来十分庞大的数据集压缩为很多特征维度,变为体积小得多的「潜在空间」,于是寻找一张图片就是像在这样一个空间里去找一个对应的坐标点,然后将这个坐标点通过一系列处理转化为图片。
CLIP
我们在使用各种在线的 aigc 服务时,经常会用到由文生图功能。为了建立文字与图片之前的联系,需要 AI 在海量「文本 - 图片」数据上学习图片和文本的匹配。这就是 CLIP(Contrastive Language-Image Pre-Training / 对比式语言 - 文字预训练)所做的事情。
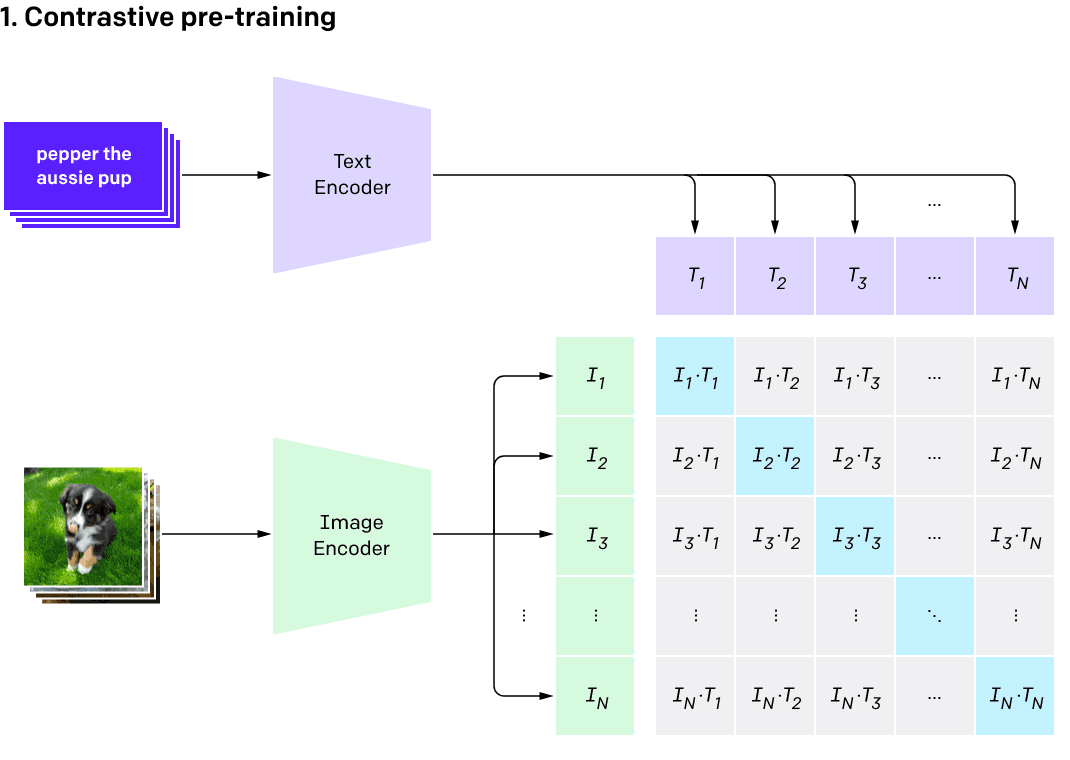
整体流程可以概括为:
- 图像编码器将图像从像素空间(Pixel Space)压缩到更小维度的潜在空间(Latent Space),捕捉图像更本质的信息;
- 对潜在空间中的图片添加噪声,进行扩散过程(Diffusion Process);
- 通过 CLIP 文本编码器将输入的描述语转换为去噪过程的条件(Conditioning);
- 基于一些条件对图像进行去噪(Denoising)以获得生成图片的潜在表示,去噪步骤可以灵活地以文本、图像和其他形式为条件(以文本为条件即 text2img、以图像为条件即 img2img);
- 图像解码器通过将图像从潜在空间转换回像素空间来生成最终图像。
工作流示例#
现在我们以这样一个需求为例:一个人想要一张「坐在天台边抬头看着镜头的女孩」插画。(图片不够大可以右键在新标签页中打开)
传统工作流#
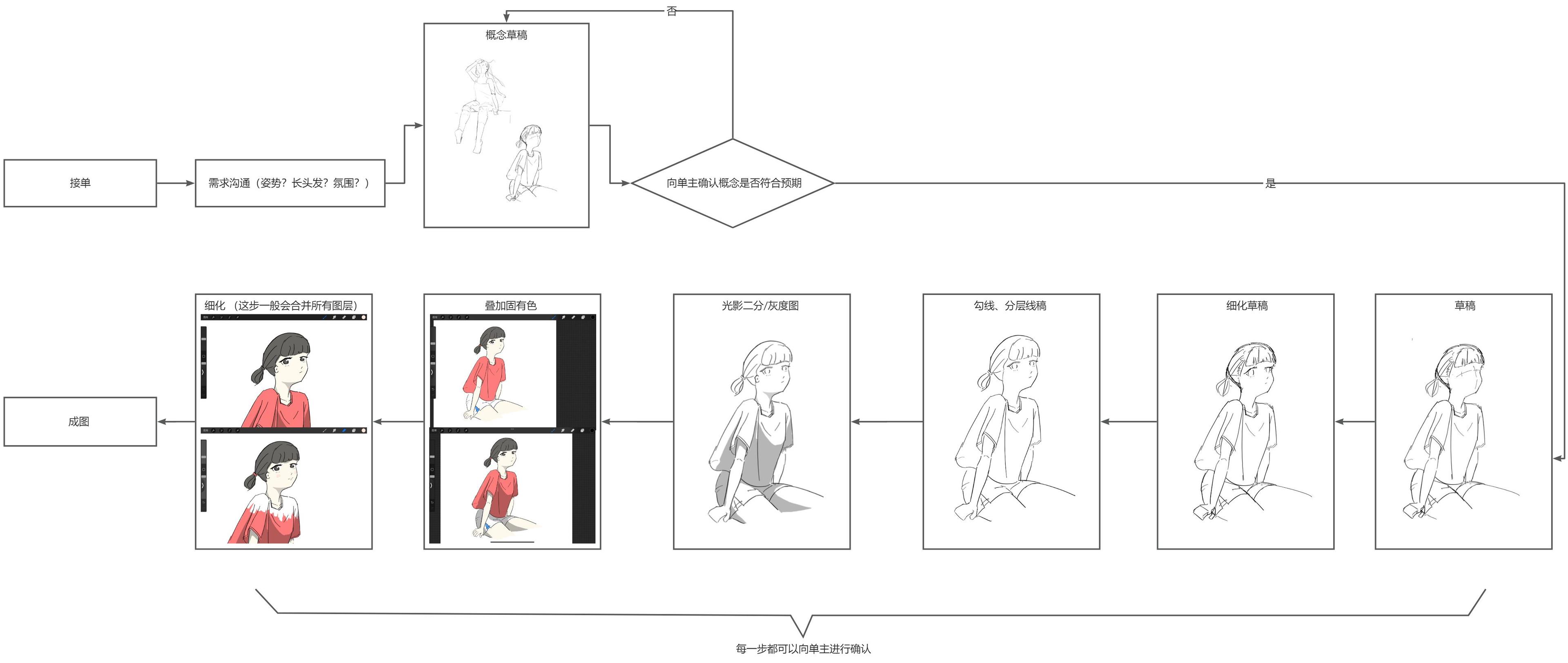
下面则是几种我用 ai 优化工作流的思路,使用的工具是本地部署的 ai 绘画最流行的工具 stable-diffusion-webui
批量概念图工作流#
需求沟通和概念草稿阶段能快速生成大量概念图,让甲方能提前预选一个它想要的图。适用于甲方需求不清晰的场景。方向确定后我们根据概念图进行创作(不是直接改 ai 的图),返工的几率大大降低。
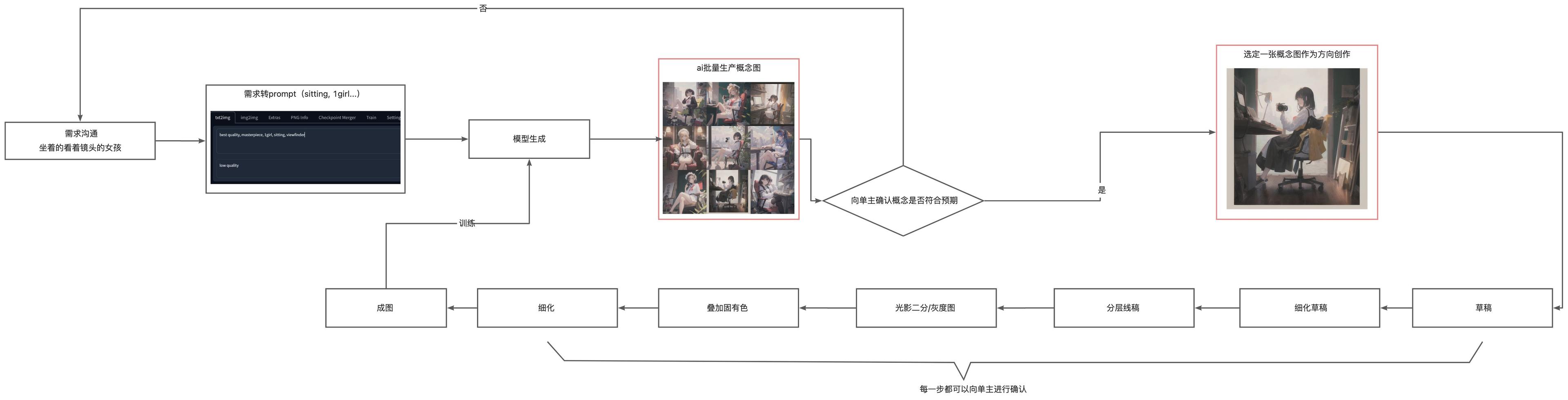
这种方式依然需要创作者亲自来创作,但因为成图都是自己创作的,所以过程中可以很好的训练属于自己画风的模型,用在以后的工作流中。
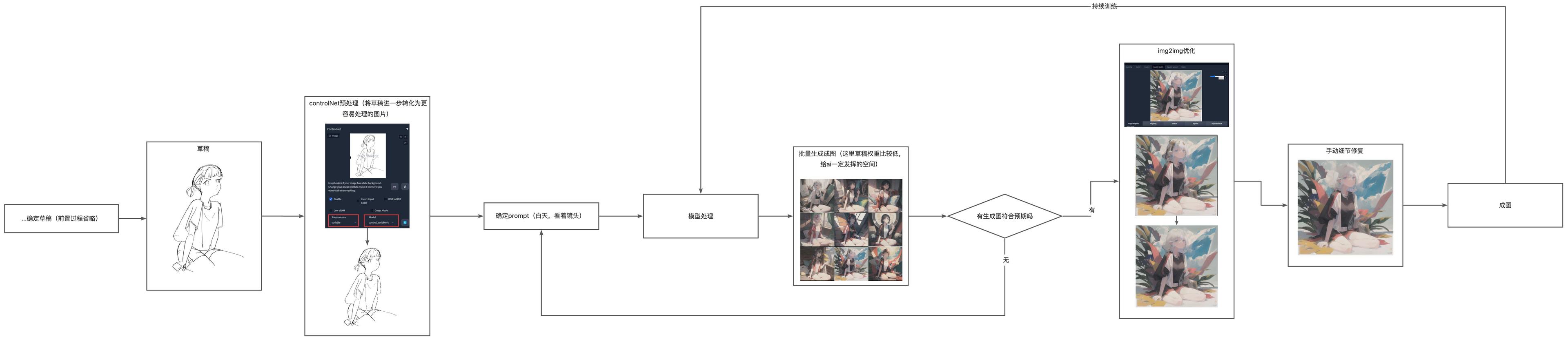
后置 AI 工作流#
将 ai 产出的图片作为结果的工作流,创作者仅需提供草稿和大致的描述 prompt,让 ai 来生成图片,这种方式能用草稿控制整体的框架,但是颜色、氛围由 ai 来处理。是我个人常用的一种,能在创作和自动化中取得平衡。
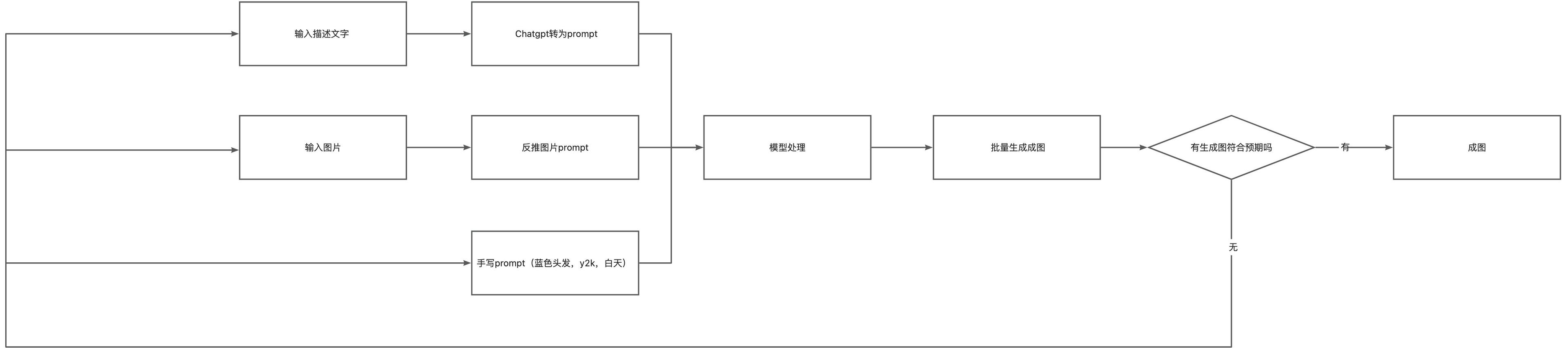
无人工绘图工作流#
另一种是直接从输入(可以是描述文字,图片,或是直接的提示词)生成图像的工作流,自动化进一步提高,但我个人不太喜欢这种方式,仅适用非常简单,要求不高的单子,或者你的模型已经训练的非常完备了,咸鱼中那种自动发货的 ai 绘图基本是使用的这种方式。
上面列举了几种我之前尝试过的工作流,但是这几种工作流也完全可以自己根据场景来裁剪和组合。在你用优质的产出图片持续训练自己的模型后,就可以得到一个拥有个人画风的模型。
这是一组训练为吉普力工作室画风的 LORA 模型混合了其他底模产出的头像,加上了 "flower" 提示词:












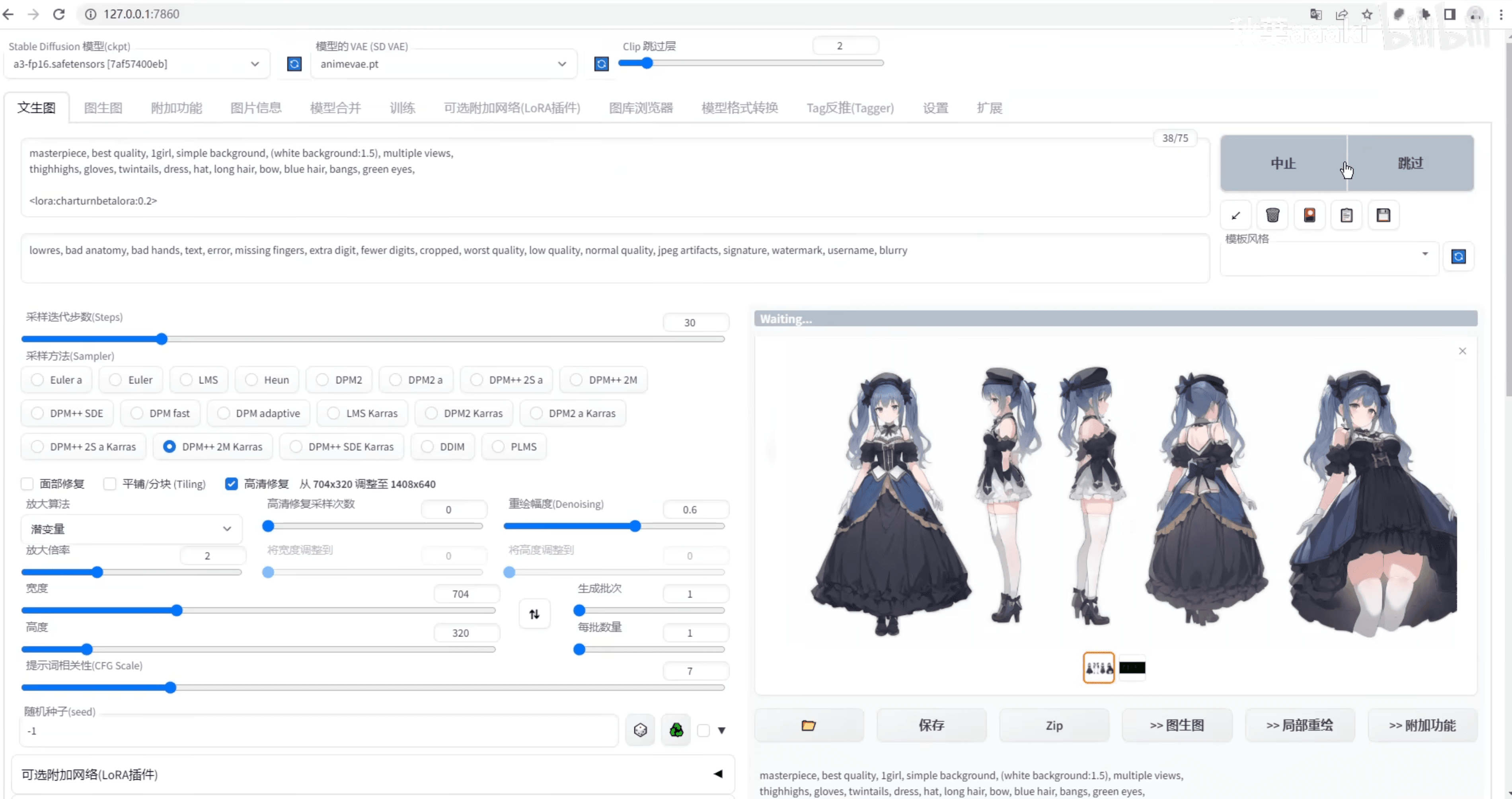
除了这些,stable diffusion 还可以配合其他插件做很多事情,比如一键生成三视图,作为角色设计前期的参考,缺少专业美术资源的项目甚至可以直接就用这些素材。(想象一下你之后花 648 抽的是这个):
※ 当前国内绘圈对于 ai 还是非常敏感,泛兴趣社区 lofter 就因为支持了 ai 生成头像,导致大量站内画师删号。
当前缺陷#
二次更改困难#
传统电子绘画中,我们会对图像进行分层,比如人物的翅膀装饰单独画一个图层,中期就可以随意更改翅膀的位置,如果要做骨骼动画,拆件也更容易。但如果我输入的图是整图,ai 也是直接出整图,这种模式并不匹配传统的分层逻辑,手动的细节修复工作量并不小,如果甲方要求二次更改插画中各个物件的位置 / 形状,因为没有分层,每一次更改都可能会影响其他的物件,而且改动的笔触和 ai 本身的画面不容易融合,整体成本不小。
如果我将手部、身体的线稿单独给到 ai,让 ai 进行处理,想让它产出分层的部件,其他的部件也都重复这个流程,最后将身体、手等 ai 处理后的部件拼接到一起。单独处理,最后合并,这听起来是一个更理想的流程,但是每一个部件单独给到 ai,会让最后生成的各个部件统一性不足,比较割裂,比如生成的身体中的衣服是一种风格,而生成的手臂的袖子可能会与身体衣服有差异。因为他们是分开处理的而不是统一处理的,ai 无法很好的将他们关联起来。
产物逻辑统一性缺失#
在工业美术中,不仅要求单张图的细节达标,同样要求整个美术资源的统一性,比如人物 A 上有固定的一个 logo 物料,在同系列人物 B 上面也有同样的物件,这在「逻辑上」是一样的东西,但是目前的模型跑出来很可能两个人物的 logo 物件是有一定程度的不同的,虽然差异不大,但这在逻辑上是不允许的,logo 形状只要有些微的差别、或者多了其他元素,就会让人感觉是两种物件,无法发挥出「统一物件」本身的作用。



如果是对细节要求不高的插画,或者前期用来脑暴的概念图,很适合 ai。
如果是严谨的游戏美术工业中的美术资源,当前 ai 目前在可控性、二次创作能力上还是欠缺了一点。
但按照现在的进化速度,相信在不久的将来上述的问题都会有相应的解法。
珍妮纺织机#
在许多的 aigc 支持者言论中,「珍妮纺织机」常常会被提出来用来类比当前的 aigc,认为 aigc 是下一个珍妮纺织机,能够改变当前艺术创作的生产关系,将反对者比作是当时打砸机器的「反动纺织工人」。这样看未免有点太社达主义(即优胜劣汰,强者生存),从产出的产品来看,纺织机产出的衣物和艺术创作者产出的艺术品是两个维度的东西,前者是更看重产出结果的生活刚需,后者则是更看重创作过程的精神消费品。我们看到梵高的自画像时能联想到他悲惨的一生,每一块颜料的纹理,每一个线条笔触都是由他亲手勾勒,这些种种融合进欣赏体验中,是 aigc 几秒产生的画作从根源上不具备的。
在以前,人作为艺术创作的主体,人这个主体本身也是创作的一部分,创作者和创作过程中的「故事」是产品的一环,为廉价品注入故事是消费升级的手段之一,这个属性在 aigc 出现后也并不会变,它拉高了最低水平,减少了社会必要劳动时间,但是富人的钱依旧用不完,该升级的消费依旧还是会升级。只是在某些不那么看中故事性的场景,比如下沉的廉价装饰画产品,aigc 的优势就会非常明显了。
未来#
ai 其实之前在创作领域已经有很多应用了,比如 Photoshop 的抠图和魔法选区,但现在之所以现在很多人感觉到冲击,还是因为发现 ai 可以直接产出最终的产品,取代自己的位置,它不再仅仅是一个工具,而是在工作属性上可能能与自己平起平坐的存在。对于我所了解的一些职业,如漫画中的勾线助手,动画中的中割,个人感觉将来基本必定会被取代了。某个评论区截图,我不保证真实性:

但是我个人仍然觉得 2d 艺术如动画不会也不应该完全被 ai 取代,引自 b 站 up 主对新海诚访谈中的一段话,关于动画中的背景图:



在动画中哪怕是一帧背景中的一片叶子,也可能因为创作时正好下着雨,于是创作者就在叶子上加了一两滴露珠。
你学到的每一个概念,你经历过的每一种情绪,以及你所看到、听到、闻到、尝到或触摸到的一切,都包括关于你身体状态的数据。你不会以这种方式体验你的精神生活,但那是‘幕后’发生的事情。
如果之后 ai 动画普及,你在看一部动画时,动画前期都很完美,但突然有一帧 ai 生成了一个不合逻辑的物件,你看到了,就算仅仅是一帧,它也会瞬间将你从 ai 编制的美梦中抽离出来,就像恐怖谷理论一样。
相比于 2d 艺术,3d 创作因为工业属性更强,流水线分层更清晰,和 ai 反而相性更好。比如最近出的能一键替换人物,自动打光的工具 wonder studio。且它最实用的是可以生成骨骼动画的中间层,支持二次修改。相比于昂贵的动捕,这种方式的成本会低不少。
但相比以上种种,还是 ai 直接生成摄影作品会更让我感到恐怖。一个人可以在几十秒内创造一个不属于这个世界任何一个地点的空间,打破了摄影的真实性和记录性。

可能 2030 年,ai 摄影泛滥后,你看到一张风景摄影图的时候,第一时间不是从心底感叹这构图这光影这山这水,而是先去怀疑这是不是 ai 生成的,拍摄的人到底是否当时呼吸着那里的空气,感受着那里的阳光,为当时空间中各种反射光打到视网膜产生的神经信号产生的内啡肽作用下举起相机,按下快门,定格世界上某个地点某一时刻的某一瞬间。当然,他也可以让 chagpt 辅助他编造出他是经历过这些过程最后产出了这张作品。
我们能做些什么#
作为程序员,我以前经常陷入一个误区,就是对于某一个领域我必须要从底层学起才能算 “入门”,但是当前的 ai 已经有非常多十分方便的上层应用,如果基础不足,直接从这些普遍使用的上层开始也未尝不可,然后利用自己能力去添砖加瓦。比如我对 ai 的基础非常薄弱,那可以基于现有的服务去训练微调模型(如 openai 的 tuning model),用在更细分的领域;我只会 curd,我就调用它们的 openapi 去做服务封装;我只会前端,我就开发一个更好用的 ui 界面;我只会画画,我就尝试用当前已有的能力看如何优化我的工作流提高效率,这些都是不错的实践。
结语#
当前人类在某些细分领域看起来已经不及 ai 了,ai 多模态的能力相比之前也取得了不小的进步。但直到现在人脑甚至人体也存在着大量黑盒,chatgpt 力大飞砖展现出的智能也和人脑的实际运行有不小的区别,人脑的效率相比机器依然很高(以 GPT-3.5 为模型的 ChatGPT 模型为例,训练一次的成本要 460 万到 500 万美元。),细分领域方向的 ai 目前看来也比强人工智能方向的 ai 性价比更高,可见的时间内,我们还不需要担心被完全取代。
但就像需要学会如何与人打交道一样,将来我们大概率也需要学习如何与 ai 交流合作,如何用更精准的 prompt 向 stable diffusion 描述画面,如何用更清晰的语句,更合理的诱导向 chatGPT 提问、构建上下文,以便更快的得到想要的结果。
当前人类的多模态、泛化能力依然还是很强大,无法量化的共情、好奇心等也一直在默默地推动着社会向前。我一定程度相信星际穿越中的 “only love and gravity”。理性上,看着天空没有任何意义,但可能正是第一个仰望星空的猿人的好奇心,让我们能走到现在。